How I Built an Agent Factory That Ships Code While I Sleep
Wednesday, 1 April 2026
We are past the hype phase of AI coding assistants. Copilot, cursor-style autocomplete, and chat-based code generation have been tried by most teams. Some got real value from them, while others didn’t.
But the next step fewer people are talking about goes entirely beyond these initial applications. It’s about agents that work autonomously and own the process from picking up a ticket to merging a pull request without anyone asking. Big companies like Stripe and Spotify are already investing heavily in this shift.
The workflow runs on a schedule. An agent reads your project board, picks the most isolated issue, creates a branch, implements the solution, and submits the PR. You go to sleep, the agents keep working, and you wake up to a notification saying the code is ready for QA.
I have been running this on IGNIO for 10 days with massive results: 182 PRs merged and 206 issues closed. The number of tickets looks high, and that is on purpose. It’s part of a strategy I adopted. Most of that shipped while I was asleep or spending time with my family.
Keep It Simple
The setup is intentionally barebones. Cron jobs trigger agents on a schedule, a rules markdown file defines how each agent behaves, and a CLI coding agent does the actual work. There are no custom frameworks orchestrating things, no elaborate harness wrapping the process, and no gigantic config files trying to cover every edge case.
This simplicity is deliberate. Every new model generation changes what agents can do, and complex setups become dead weight the moment a better tool arrives. I’ve read about teams build elaborate orchestration layers around GPT-4 that became obsolete when Claude Code Opus 4.5 shipped with native tool use. The simpler your system, the faster you can swap the engine without rebuilding the car.
The patterns that matter eventually get absorbed into the official tools. Planning started as a community hack with markdown files, skills emerged from people building prompt libraries, and memory went from Redis workarounds to first-class features. What survives long-term is the architecture around the agents, not the clever hacks inside them.
Context Discipline
The instinct when setting up an agent is to give it everything. You might want to include the full codebase context, all the documentation, the issue description, the conversation history, and related PRs. The thinking is that more context means better output, but in practice, the opposite is true. The more context you dump on an agent, the worse it performs.
You need to be surgical about what goes into the prompt. Give the agent only the exact information it needs for this specific task:
- A clear issue title
- A focused description
- The relevant files
- The rules that govern how it should behave
This is why breaking work into atomic issues matters. A ticket asking to improve the transaction flow is terrible for an agent because it is vague, touches multiple files, requires subjective judgment, and has no clear stopping point. Compare that to a ticket stating that email preferences default to false when subscription tiers are bypassed, causing reminders to silently not send. The agent knows exactly what is broken, where to look, and what success looks like.
That strategy is the exact reason I was able to close those 206 issues. By keeping each ticket small and limited to a single bug fix or service, the agent could easily hold the entire problem in its context window without getting distracted by unrelated code. Ultimately, smaller tickets lead to less context pollution, fewer hallucinated connections, and a much higher first-pass success rate.
The core principle is to separate the research from the execution. You decide what to build and how it should work, and the agent builds it. If you find yourself explaining both the problem and the solution in the same prompt, you have already done half the work yourself. Write a clear issue and let the agent figure out the implementation.
“Done” Is Provable
Every agent run needs an explicit stopping condition that the system can verify on its own, rather than just assuming the code looks right or relying on the agent claiming it works. A task is only finished when tests pass, CI is green, and a PR is opened with a description explaining the reasoning.
Think of it like a loop with a break clause. Without a clear exit condition, agents tend to drift by implementing stubs that technically compile but fail the moment a real user touches them. I saw this early on when my agents would open PRs with placeholder implementations that passed linting but had zero behavioral tests, making the work look complete when it actually was not.
Adding a mandatory test step eliminated that problem entirely. If the tests do not prove the behavior changed, the agent keeps working. If CI fails, the ticket stays out of the review queue. Because the stopping condition is binary, there is no room for the agent to declare victory prematurely.
Short Sessions Over Long Ones
Each agent run gets a fresh session tied to a single issue and a single branch. When the work is done, the session dies. This guarantees the next cron cycle starts completely clean with no memory of what came before.
I avoid running agents for extended periods. Long sessions accumulate context from previous work, causing the agent to hallucinate connections that do not exist. It might reference variables from a file it edited hours ago that has since been rebased, or apply patterns from a previous ticket to a completely unrelated one. The longer the session runs, the more phantom context bleeds into the output.
I learned this during a painful debugging session where my agents were stalling for hours with no output. The root cause was a session timeout killing them mid-execution, but the real lesson came after I extended that limit. Agents running for two hours produced noticeably worse code than those finishing in 30 minutes. Shorter runs maintain tighter focus and deliver cleaner output simply because they never have time to accumulate noise.
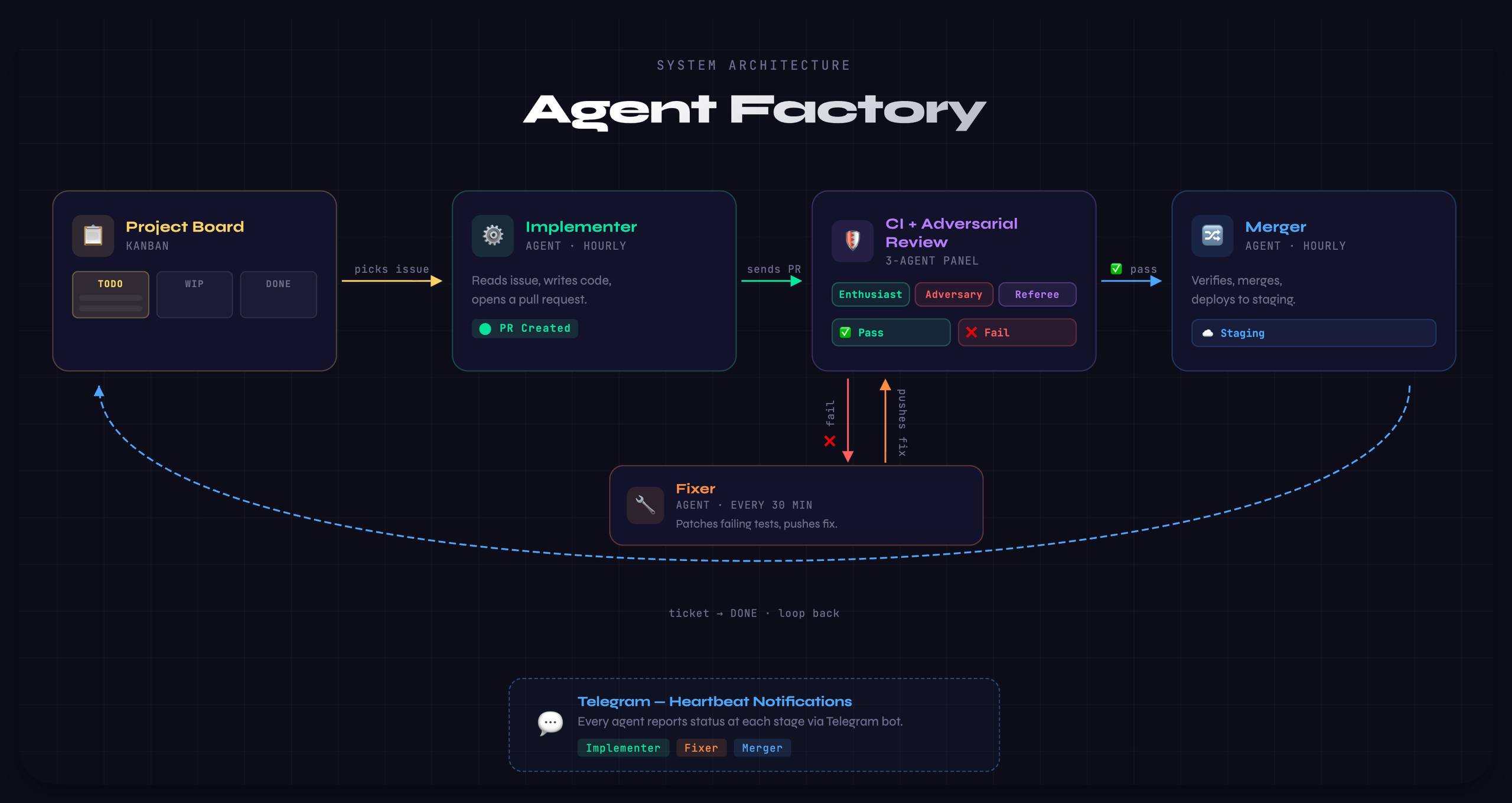
The Three-Body System
Separating the roles was not the original design. I started with a single agent that handled everything: implementing code, watching CI, fixing failures, and merging. Because it was constantly blocked waiting for pipelines to finish, the entire process was slow and fragile. Splitting the system into three distinct roles changed everything.
The Implementer runs every hour, querying the project board for the most isolated issue in the current milestone. Once it picks a ticket, it creates a worktree, reads the documentation, implements the solution step by step, writes tests, and opens a PR. Because each issue is deliberately detailed with expected behavior, root causes, and acceptance criteria, the agent rarely has to guess.
It also follows a strict ruleset governing every step. By enforcing existing code patterns, requiring justification for new dependencies, and mandating a “Why” section in every PR description, the output remains maintainable. Instead of waiting around for CI to finish, it simply pushes the code, sends a notification, and moves on to the next task.
The Fixer runs every 30 minutes on a staggered schedule, scanning open PRs for CI failures, merge conflicts, or rejections from an automated code reviewer. When it finds a problem, it claims the PR through a locking mechanism to prevent duplicate work, pushes a fix, and moves on. If it fails to resolve the issue after three attempts, it moves the ticket back to TODO with a detailed comment explaining what went wrong.
This loop handles the tedious work that used to eat my mornings. Whether it is a lint error from a missing import or a type mismatch from a rebased file, the Fixer resolves it autonomously. That means I stop context-switching to fix pipelines and can focus entirely on product decisions.
Finally, the Merger acts as the last gate. While my job is to manually review and approve the code, this agent handles the mechanics of actually landing it. It verifies the branch is up to date with main, ensures all checks have passed, merges the PR, cleans up the branch, and triggers a staging deployment.
This separation creates resilience through isolation. If the Fixer gets stuck on a complex conflict, the Implementer keeps shipping new PRs on the next cycle. Because each agent fails independently without blocking the others, they can all start with only the context relevant to their specific job.
Adversarial Code Review
Before the Implementer pushes a PR, it runs a self-review using three competing agents with conflicting incentives. I didn’t invent this three-agent adversarial approach. It is a pattern gaining traction in the agentic coding space, rooted in the observation that LLMs are inherently sycophantic. They naturally want to agree with you. Instead of fighting that tendency, you can design a system where each agent’s desire to please works in your favor because they are all trying to please different masters.
Here is how the dynamic works:
-
The Enthusiast acts as a hyper-aggressive bug hunter. It earns points for every bug it finds, scaled by severity. Because it wants to maximize its score, it produces a massive list of potential problems, including both real bugs and speculative edge cases. That over-reporting is intentional because we want to cast a wide net early on.
-
The Adversary takes that list and tries to disprove every single item. It earns points for successfully debunking a bug but faces a harsh penalty for incorrectly dismissing a real issue. That asymmetric risk makes it aggressive about challenging weak claims while remaining cautious about dismissing anything legitimate. It actively checks if a concern is purely theoretical or already handled elsewhere in the codebase.
-
The Referee evaluates both sides without any bias. It examines the actual code, reads both arguments, and renders a final verdict: real bug, false positive, or worth noting. Since it is rewarded strictly for accuracy, it has zero incentive to blindly side with either the Enthusiast or the Adversary.
Running this in production consistently catches issues that CI alone misses. It flags type safety gaps where a cast silently drops an error, edge cases in async handling, and race conditions in queue processing. These are the exact bugs that usually only surface in production if you are unlucky, but this debate catches them before the code even leaves the branch.
Once the Implementer finally pushes, CI and the automated code reviewer take over. Any issues that slip through the adversarial review get caught there and handled by the Fixer on its next cycle. The whole system becomes self-healing: the Implementer generates, the adversarial review filters, CI validates, the code reviewer scrutinizes, and the Fixer cleans up whatever remains.
Stay Connected
When agents run autonomously, silence becomes your enemy. If an agent succeeds, you find out eventually. If it fails, you might not find out at all. You cannot tell the difference between “nothing happened” and “everything is broken” until you manually check.
To fix this, I added Telegram notifications at every stage of the pipeline: when the Implementer starts an issue, when a PR is opened, when the Fixer claims a failing build, and when CI passes. Even idle cycles get a heartbeat message: “All PRs green. Standing by.” That single line is incredibly valuable. Silence forces you to check, but a heartbeat lets you trust the system is alive so you can move on with your day.
Rules Are Your Operating System
Every time an agent does something wrong, I add a rule. The rules file is a living document that grows with every mistake, ensuring the same error never happens twice.
For example:
- Match existing patterns.
- No new dependencies without justification.
- Write tests for every behavioral change.
- Document the why, not just the what.
Each of these exists because an agent once made a bad decision that I had to fix manually.
Over time, this file becomes the best documentation your project has. Not because someone sat down to write docs, but because every lesson is captured in real time as a direct response to a failure. When agents read these rules before touching code, they inherit every past lesson without any onboarding.
But rules accumulate, and eventually, they start contradicting each other. If you tell an agent to keep it simple in one rule and add comprehensive error handling in another, it will try to satisfy both. The result is usually over-engineered code handling errors nobody will ever encounter.
Periodically, you need to consolidate. Remove what is obsolete and merge overlapping instructions. You have to refactor your rules the same way you refactor code. A lean, non-contradictory rules file produces much better agent output than a massive one trying to cover every edge case.
Continuous Improvement
The system gets better with every cycle. Not because the underlying AI model magically improves, but because your rules and issue descriptions do. Every failed agent run teaches you something specific.
The agent picked the wrong issue? Tighten the selection criteria. Its code broke a test in a different module? Add a rule about cross-module dependencies. It created a PR with no description? Enforce a “Why” section in the template.
You are training the system through experience, exactly like you would onboard a junior developer.
The difference is that the rules are permanent. A junior might forget what you told them last week. The rules file never does.
Own the Outcome
Do not assume agents will magically adapt to your codebase. They will not read your mind, infer your architectural preferences, or understand your business context without explicit guidance. Fine-tune the directives. Integrate thoughtfully. Every shortcut you take during setup costs you ten times more in cleanup later.
The agent writes the code, but you own the product. Review PRs when needed. Open follow-up issues when the execution isn’t quite right. You still need to understand the architectural decisions and maintain the overall mental model. The agent is your workforce, but you are the engineering lead.
This technology is early. It is not perfect. But it is already so powerful that it completely changed how I build.
And it is just the beginning.
Try the product this system built. IGNIO is a personal financial assistant that runs on Telegram, powered by the exact agent factory described in this post. I just launched it. The first 100 sign-ups get the PLUS plan free for 6 months. Try IGNIO →
Want this for your team? If you are interested in implementing an autoagent system like this in your company, reach out. I consult on agentic workflows, CI automation, and autonomous coding pipelines. Get in touch →